Self-Supervised MultiModal Versatile Networks
29 Jun 2020
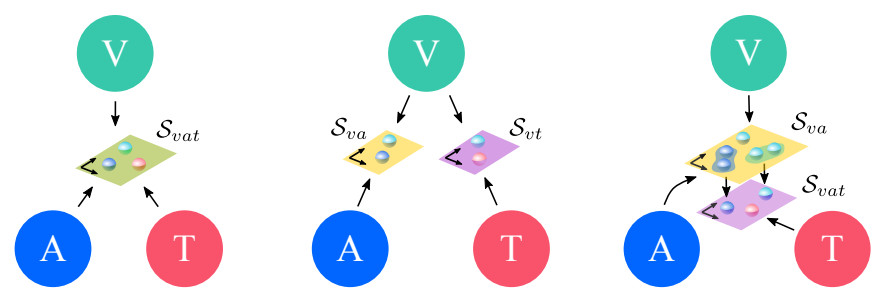
We learn representations for vision, audio and language in a self-supervised manner using millions of videos from YouTube.
We learn representations for vision, audio and language in a self-supervised manner using millions of videos from YouTube.
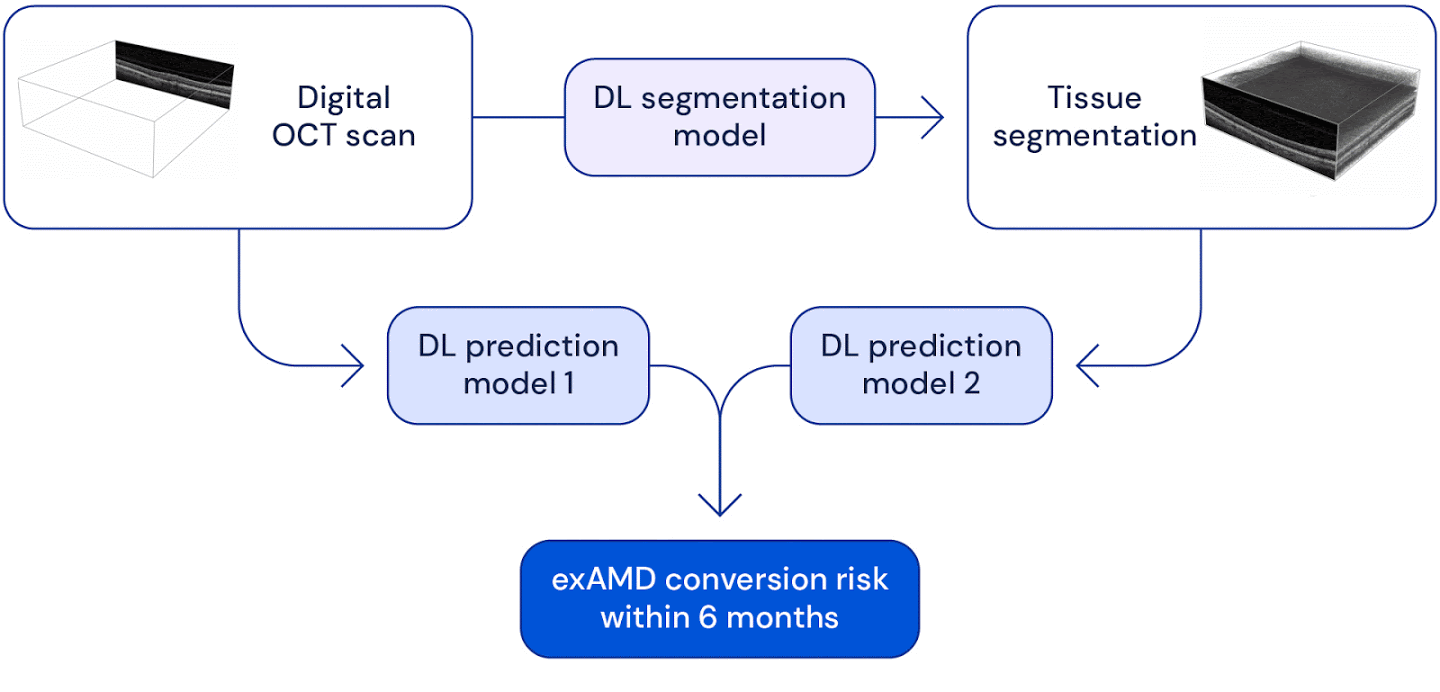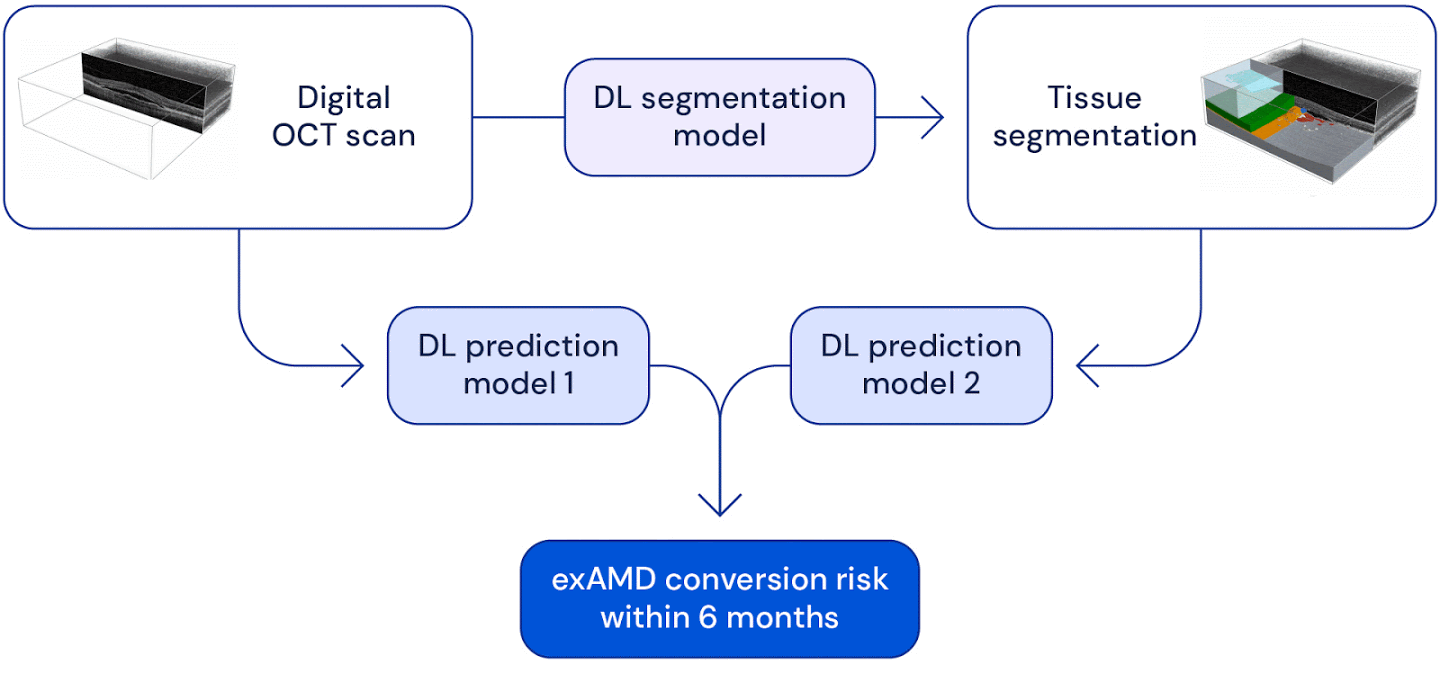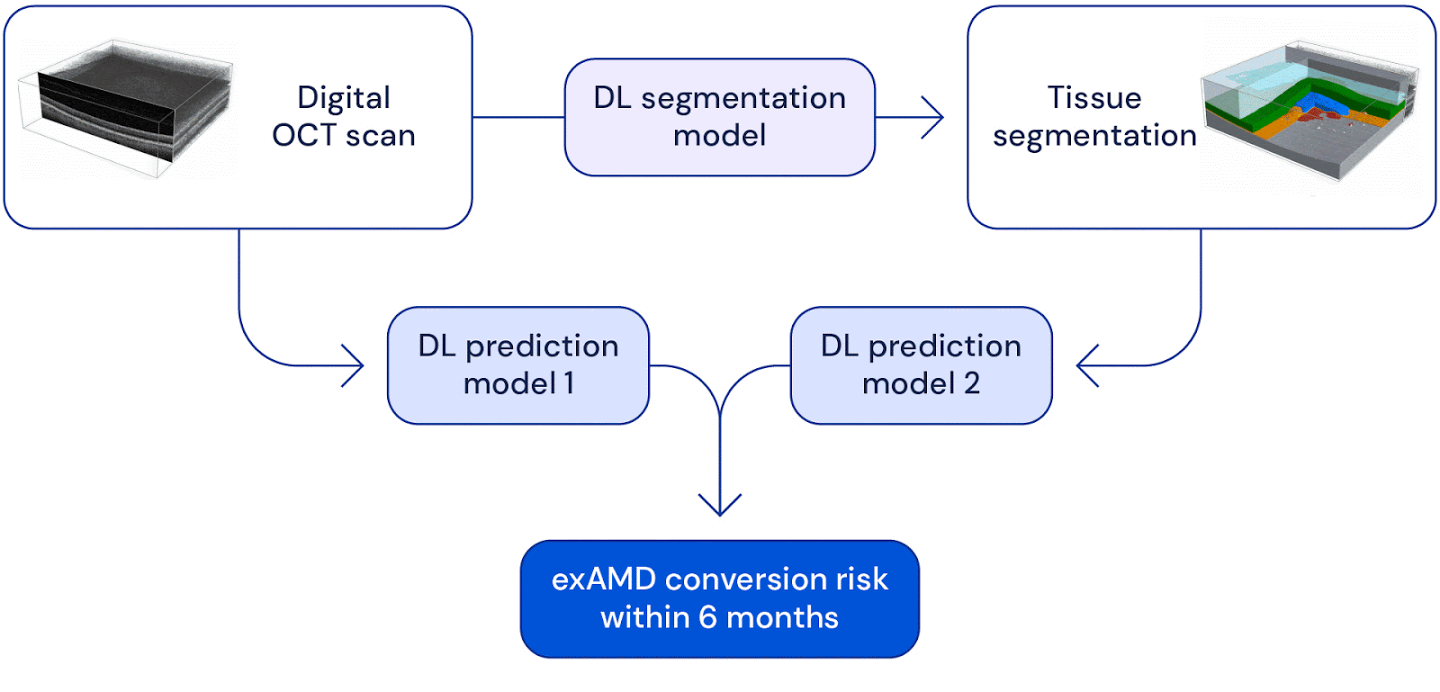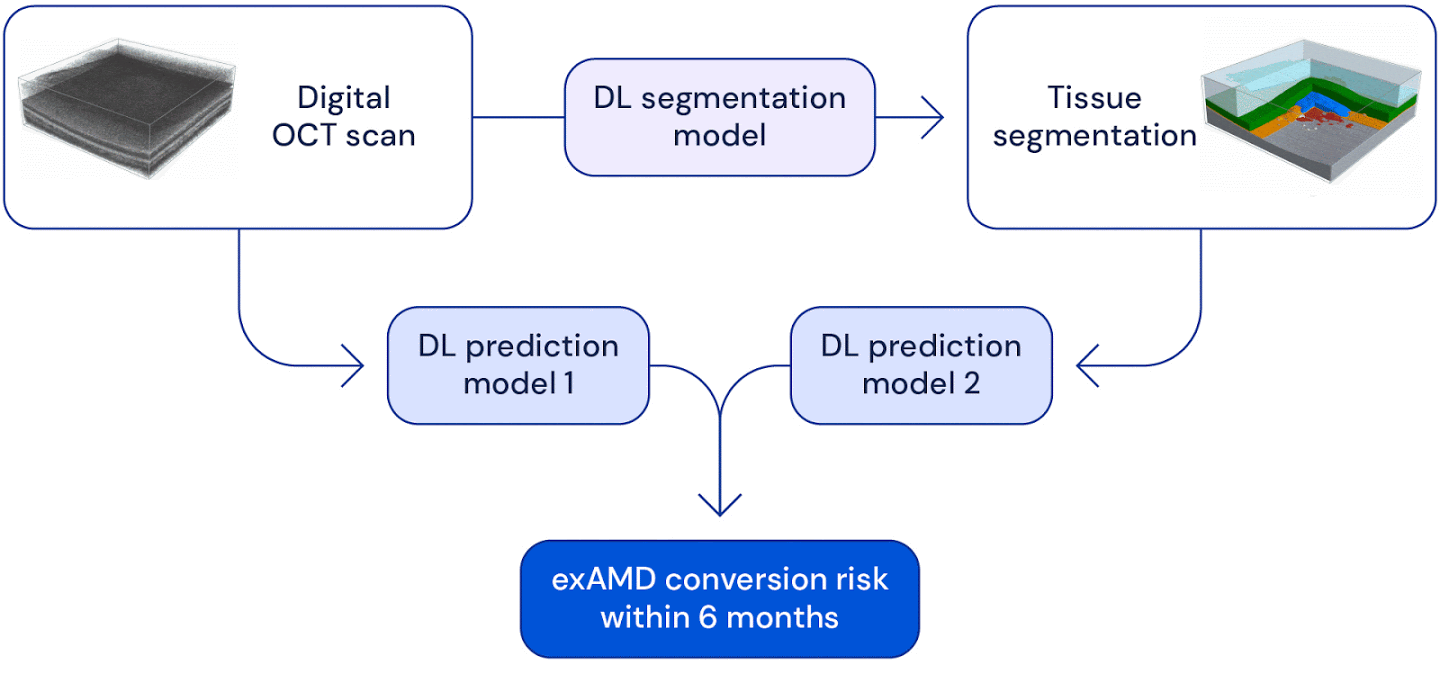
High level overview of the system used for wet AMD conversion prediction. We have two deep learning based models: one uses the original raw OCT scan to predict conversion, the other uses the the raw OCT segmented into several tissue types to predict conversion. Their predictions are ensembled to provide a single prediction of the risk to conversion within 6 months.
We look at predicting the progression of an eye to the sight-threatening form of AMD within 6 months. We demonstrate a deep learning system that is able to outperform five out of six experts on this task and importantly also overcomes the high interobserver variability from the experts.
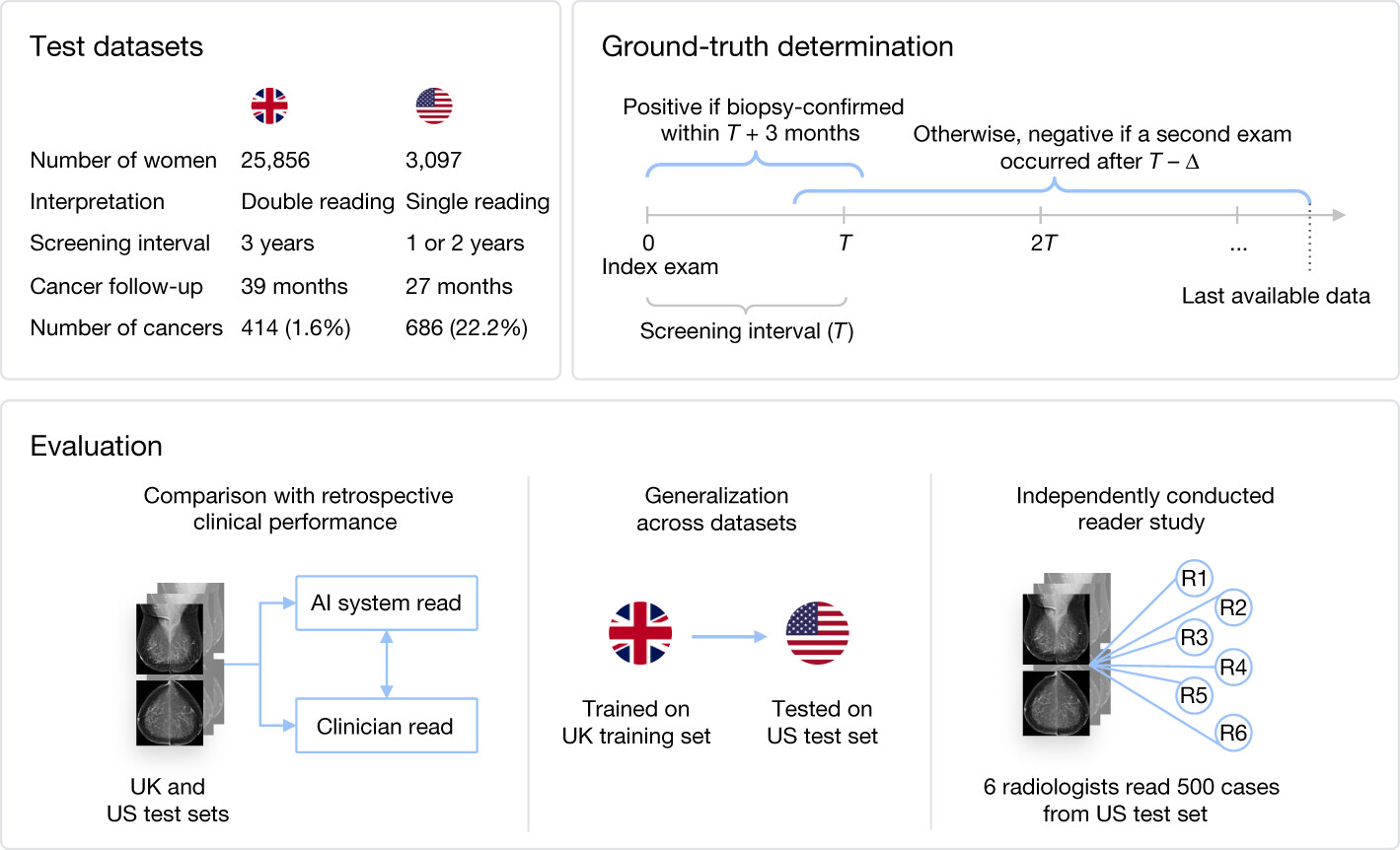
Overview of the methodology of the paper. We consider two main datasets, one from the UK and one from the US. We evaluate with retrospective clinical performance as well as an independently conducted reader study. We also investigate the transfer of performance between continents.
We demonstrate an AI system that can detect breast cancer better than human experts on a large, representative UK dataset and a dataset from the US, in the context of breast cancer screening programmes.
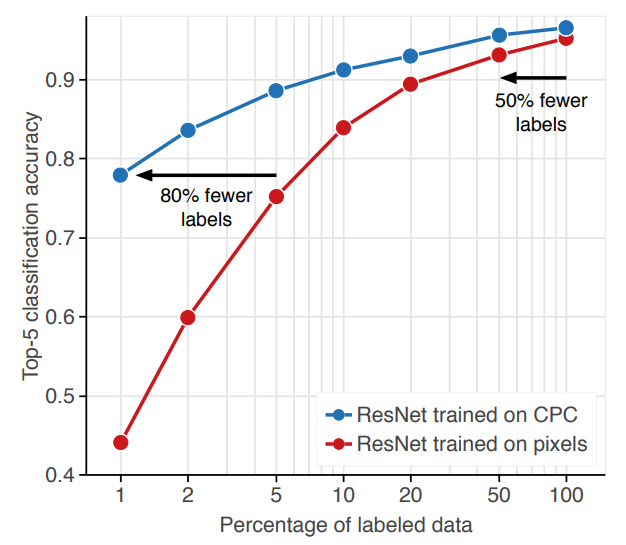
The method outperforms training from scratch for every amount of labels, even when using all labels
Beating previous state of the art in self-supervised learning for ImageNet by almost 3% absolute with less parameters (71.5% vs 68.6% top1) and outperforming purely supervised approaches in all data regimes.

256x256 class-conditional samples from our model.
We hierarchically stack discrete autoencoders to allow likelihood models to capture long-range structure in images. This allows us to generate realistic images at resolutions of 128x128 and 256x256 with autoregressive models, which had not been shown before!
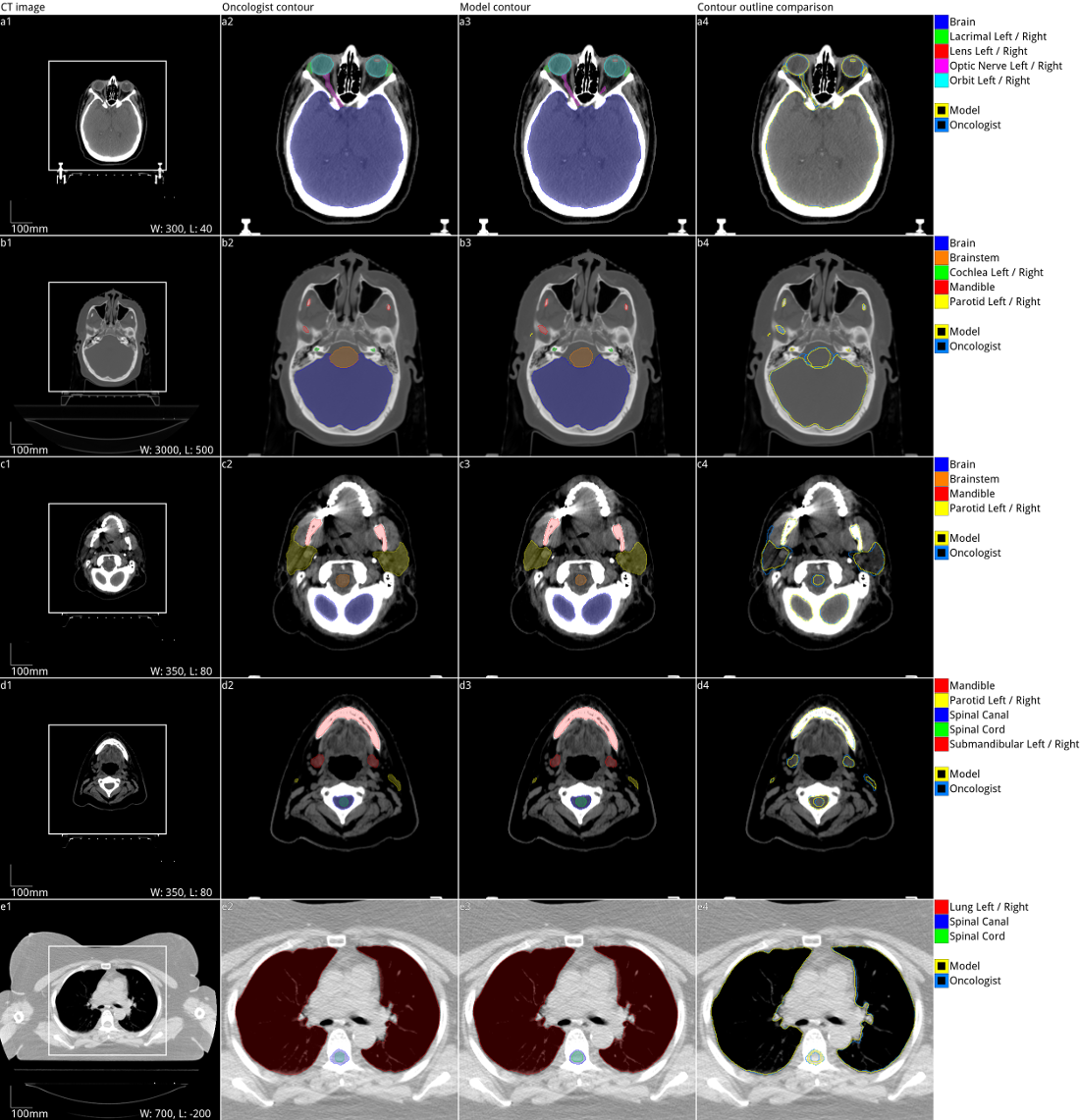
Example segmentations of the model vs the oncologist.
We propose a model for segmenting the organs at risk in 3D Computed Tomography (CT) scans for the planning of radiotherapy treatment. Improvements in such a segmentation could result in improved and faster treatment.
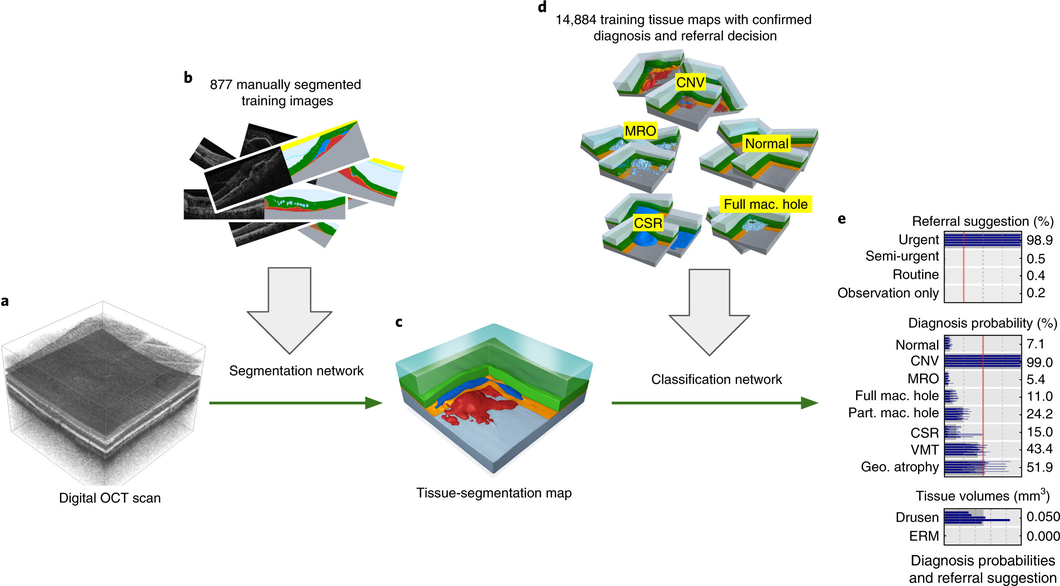
Our proposed two-stage architecture trained with sparse segmentations and diagnosis and referral labels.
We propose a two-stage architecture that consists of first mapping the original (noisy) 3D Optical Coherence Tomography (OCT) scan to multiple tissue-segmentation hypotheses, and consequently using a classification network on these tissue maps to infer diagnosis and referral probabilities. On these tasks we achieve expert-level results or better. One benefit of the two-stage architecture is that it allows for much quicker transfer to different device types, as demonstrated in the paper.
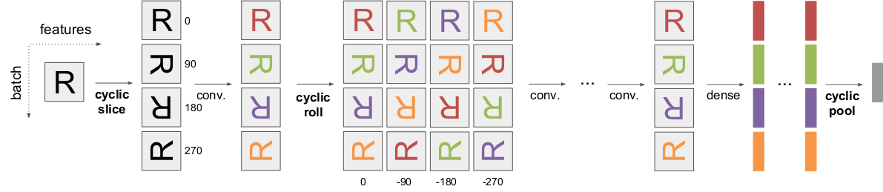
Schematic representation of the effect of the our proposed operations, cyclic slice, roll and pool, on the feature maps in a convnet.
We propose some simple, plug-and-play operations for convolutional neural networks that allows them to be partially equivariant or invariant to rotations.

Pairs of fundus images of the eye after the first layer in the convolutional neural network.
The past almost four months I have been competing in a Kaggle competition about diabetic retinopathy grading based on high-resolution eye images. In this post I try to reconstruct my progression through the competition; the challenges I had, the things I tried, what worked and what didn’t. This is not meant as a complete documentation but, nevertheless, some more concrete examples can be found at the end and certainly in the code. In the end I finished fifth of the almost 700 competing teams.